PDF Reader
PDF Reader node is used to read the contents from a text PDF. The below steps need to be followed:
- Configuration: Select a PDF configuration from the drop down. Refer to Task Design -> Configuration for setting a Document configuration
- Mappings: Provide the Location where PDF is saved in the input mapping section. The PDF files should be placed in the Windows server where Jiffy service is running. Refer to Mapping section for details on providing input mappings.
- Template: Template flag need to be turned on/off. In case an XML Template has been created, turn “Template” flag to ON.
- Template Tag: Provide the Template tag that is saved by creating the template Refer Repository - Document Templates for more information
Obtaining PDF data with Template Flag as OFF
When the Template Flag is OFF, the data can be mapped from the segment (eg: /root/pdfoutput/pdfdata/document/pages/page/lines/line[19]/segments/segment[2]/@text). The segment and line number would depend on the PDF XML output.
Obtaining PDF data with Template Flag as ON
As a pre-requisite, the Template tag need to be provided for matching the template with the PDF.
Jiffy would validate the PDF document against each template with the same tag. Once a matching template is obtained, Jiffy would mark the Output variables and the table list data in the Output section, along with the XML Data. The output variables can be mapped to further nodes. ie. The data which is read from the PDF can be passed to the subsequent nodes.
Please refer to Repository - Document Template for more information.
Output Result Display
The ResultText would contain the PDF with green boxes which indicate the data that has been captured using the template. The Output would contain the XML file based on the PDF template.

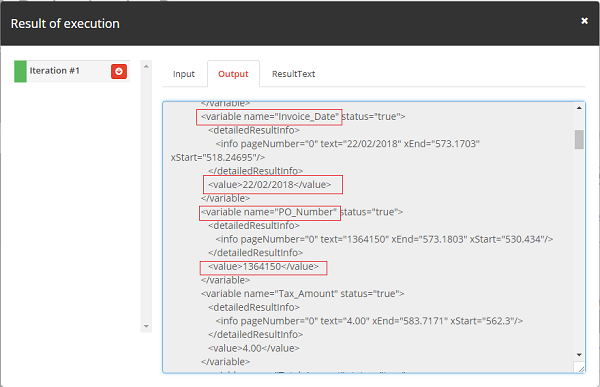
Note: Keep a track of the variable names you assign and use them accordingly. Incorrect uses will lead to malfunctioning of the task.