8. Document Templates
Document Templates are used to upload the PDF templates that will be used for reading the data from the PDF file. The files loaded here will be available as dropdown option for user to choose in task design.
The following are the different functionalities available:
Add template
Add new document template to repository. User can use the help button next to Add template to get instructions on how to create the XML template.

The PDF document template contains the following subsections:
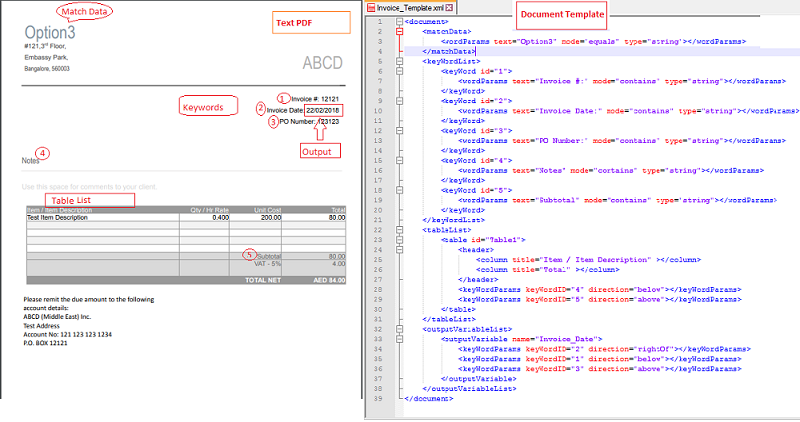
- MatchData (Mandatory) - Matchdata is used to identify the PDF document. User needs to provide unique text from the PDF as Match data. Based on the value for mode parameter, Jiffy tries to match the template with the PDF. For eg: If mode is given as “equals”, Jiffy would try to find an exact match as given in the template against the PDF.
- keyWordList - Keywords are used to identify unique texts in the PDF. Only one wordParams per keyword. There can be any number of keywords present in a template. The keywords are used to provide the location of output variables.
- Keyword split: This functionality is used to identify the data of the specified keyword in the document template.
If the specified keyword is found, then it looks for a delimiter (Semicolon, colon, hyphen, dot, and space) following the keyword to separate and capture its data.
Example:
Invoice: 12345678
Specified Keyword: Invoice
Data captured: 12345678
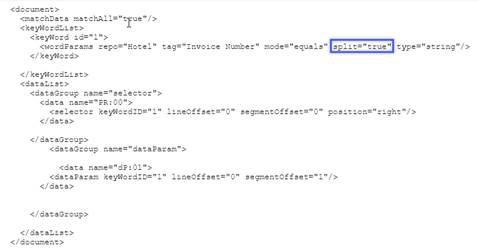
“Now the changes have been made such that in the Document Template, the split parameter is set to false by default. Based on the requirement, the user must set the split parameter to true for the specified keyword in the document template manually.” - Selector: A new functionality called Selector is implemented in the document template as a part of the Reading PDF functionality.
Using the Selector functionality, the user can extract data related to the specified keyword from the PDF based on the following four parameters:- Position: Set the position (right, left, top, and bottom) based on the direction in which the data needs to be captured.
- Segment offset: It is an integer value. The first segment value is considered as “0” and the value increments for the consecutive segments.
- Line offset: It is an integer value. The line offset value is “0” for the nearest data and the value increments based on the distance from the specified keyword.
- Segment Threshold: A threshold distance is provided to capture the data as a single entity if the data is within the given distance from the specified segment.

- Keyword split: This functionality is used to identify the data of the specified keyword in the document template.
If the specified keyword is found, then it looks for a delimiter (Semicolon, colon, hyphen, dot, and space) following the keyword to separate and capture its data.
- tableList - To fetch the data from the tables available in the PDF document. Multiple tables are allowed. User needs to provide the table headers as-is from the PDF to fetch the data of those respective columns. If table data is not present, user can delete the table section from XML.
- outputVariableList - Output variables to extract data from PDF. Multiple outputVariable are allowed. Multiple keyWords are allowed per outputVariable. For each output variables, keywords need to be provided along with direction. For eg: To fetch “Invoice Date” which is present in PDF. First multiple keywords need to be identified near to Invoice Date field. If invoice date is written next to the text “Invoice Date”, above “PO Number” and below “Invoice #”, 3 keywords need to be defined. In the output variablelist section, for the output variable “Invoice_Date”, use these keywords along with direction like KeywordID=“1” Direction =“rightOf”
- TemplateComment - any comment which can be used later for template specific processing.
Example PDF and Document Template
Add Template Tag
Template tags are required to match the template with the Text PDF. The same tag can be provided to multiple templates. In Task Design -> Properties, when the tag name is provided, Jiffy would validate the PDF document against each template with the same tag.
For eg: If two templates has the same tag, the PDF document would be matched with both these templates based on the matchdata.
To add a Template tag:
- Click on the Document template under Document templates section
- The Edit template page will be displayed. Click on Edit
- Add the tag required for identification and Enter.
- Click on Save to save the changes
View XML
The document template can be viewed as tree data or as Raw Data
Upload or Replace template
This is to make modifications to the document template. If there are changes to be done on template, users will be able to replace the templte with the new one using a single click.